


模块的导入 
介绍— “不要因为没有掌声而丢掉梦想,未来日子还长,请保持好心情”
模块是在 Python 中用于组织、重用和封装代码的文件。在 Python 中,模块也可以简单地理解为一段 “Python 程序” ,我们在前面的教程中学到的各种结构、函数、类等等都可以作为模块或者模块的一部分。
想象一下,我们正在整理家里的衣柜,衣柜里有很多可以抽拉移动的收纳柜,收纳柜里面放着很多衣服、裤子或者配件的组合,我们可以通过收纳柜一次性取出一系列想要的物品。
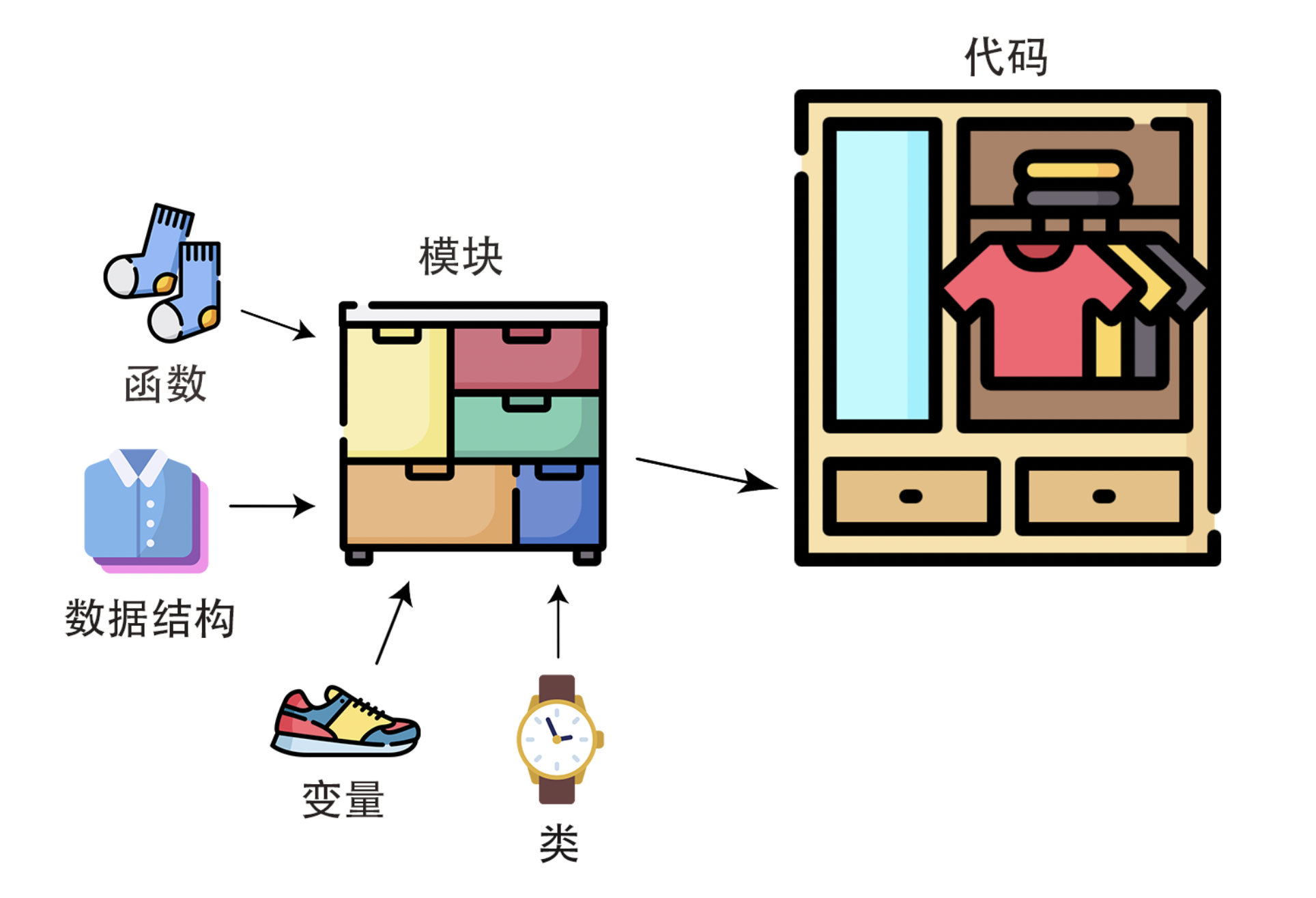
在上面的这个例子中,衣柜是一个很大的容器,相当于我们的整个 Python 代码,收纳柜里存放的各种物品相当于类、函数、变量等元素或者数据结构,而收纳柜就相当于模块,它在柜子中起到了归类、整理、收纳的功能,在想用的时候直接取出收纳柜可以了,在程序中模块也是扮演这样的功能。
另外,在上面的例子中,我们可以根据自己的喜好将不同类型的物品放在不同的收纳柜里,比如一个收纳柜是专门用来放袜子的,另一个收纳柜是专门用来放鞋子的,这样衣柜就会整齐有序,方便查找和管理。
在 Python 中,使用模块有非常多的好处,比如在编程时有一些功能没必要自己费劲去编写,可以借助 Python 内置的标准模块或者其他人编写的第三方模块直接来完成想要的功能,比如我们之前在教程中接触到的 random 库,用来生成随机数。里面的算法已经由其他开发者设计好了,我们只需在自己的程序中调用就可以。
总之,模块提供了一种机制使我们可以在不同的程序中重用代码。可以将常用的功能封装在模块中,然后在需要的地方导入和使用它们,避免了重复编写相同的代码,提高了开发效率。
【关于封装】其实我们在前面的教学中已经接触过了很多封装方法,比如数据结构是对各种类型的数据进行封装、类是对变量和函数的封装,而模块的封装可以理解为对代码的封装,把具备某些特定功能的代码写到一个单独的文件中,作为独立的模块,这样可以方便其他程序进行调用。
模块的引用
模块是一个独立的 Python 文件,文件的后缀是 .py 。在我们下载 Python 后,系统会默认自带很多标准模块的文件,并部署在环境变量中,我们可以在程序中直接引用。
调取模块需要使用 import 关键词来完成,写法主要有下面两种方式:
# 方式一import 模块名 as 新名称# 方式二from 模块名 import 函数/类/变量名称 as 新名称两种写法后面接的 as 新名称 都可以省略,让我们直接来看一个案例:
【示例】引用 math 数学模块计算平方根
# 引入数学模块import math as mt# 使用该模块计算平方根sqrt(9)# 输出结果print(result)在引用模块后,可以根据自己的喜好,使用 as 关键词赋予模块新的名字,上面的例子中我将引入的 math 模块赋予了 mt 的名字,在后面可以直接使用 mt 来调用内部函数。当然,如果模块名称不长的话可以选择不修改,as 关键词和后面的名称可以省略。
【路径问题】让我们来看一下当代码执行到 import 关键词的时候程序都发生了什么? 当 Python 程序中出现了 import 关键词,程序会先在当前的运行的文件路径下,也就是同级目录,去寻找对应名称的模块。
如果同级目录下没有找到模块,会到系统路径 sys.path 中去寻找,该路径包含标准库安装目录和其他自定义路径。当然,我们可以自己定义导入模块的路径,系统路径可以在 sys 模块的 path 变量中查询,我们通过代码来查看该路径:
import sysprint(sys.path)当你运行上面的代码,程序会输出此时系统路径的位置,结果会用一个列表来呈现,不同用户的结果可能不同,根据输出的结果,我们会知道目前哪些路径可以直接在 Python 程序中直接引用,我们可以将创建的模块放置在上述目录下面,这样就可以直接调用了。
当然,如果我们有自己喜欢的路径,希望能新增到环境变量中也是可以的:
import sys'在这里填入你的新路径'append(new_path)通过上面的代码,就可以将模块放在对应的新路径下,在 Python 中也可以直接调用。
让我们再来学习一下使用 from import 来引用模块中的函数或者类或者变量:
【示例】引用 math 数学模块中的 sqrt 函数来计算平方根
# 引入数学模块中的 sqrt 函数from math import sqrt as s# 使用该模块计算平方根9)# 输出结果print(result)在 Python 中使用 from import 关键字会直接从模块中选择特定的函数或者类或者变量,并可以直接进行引用,不需要再加上模块的名称,和直接 import 相同,在后面可以对函数、类或者变量进行命名,在后面可以用相应的名称直接引用。
下面是一些常见的内置标准库,可以做粗略了解,在后面的教程中部分模块会做深入学习:
| 模块名称 | 描述 |
|---|---|
| os | 提供与操作系统交互的功能,包括文件和目录操作、进程管理等。 |
| sys | 提供对Python解释器的访问和控制,包括命令行参数、标准输入输出等。 |
| math | 提供数学运算的函数和常量,如三角函数、对数函数、常用数学常量等。 |
| random | 用于生成伪随机数,包括随机数生成器和随机选择功能。 |
| datetime | 用于处理日期和时间,包括日期时间的创建、格式化、计算等操作。 |
| json | 提供 JSON 格式文件的编码和解码功能,用于处理JSON格式的数据。 |
| re | 提供正则表达式的支持,用于字符串的模式匹配和替换,是非常强大的文本处理工具。 |
| time | 提供与时间相关的功能,如睡眠、时间戳等。 |
| logging | 提供灵活的日志记录功能,用于应用程序的日志记录和调试。 |
模块的创建
在上面教程中我们调用的模块都是系统标准模块,也就是下载 Python 的时候自带的模块,当然我们也可以创建属于自己的专属模块,供项目后续随时使用。
在 Python 中,模块的创建都是在一个独立的 Python 文件中,文件的后缀是 .py ,将写好的文件放在我们运行的脚本同级目录下就可以完成调用。
【示例】首先,我们创建一个新的 Python 脚本,命名为 my_model.py 在里面写上如下代码:
# !/usr/bin/python3# Filename: my_model.py# 创建一个变量'牧旗教程'# 创建一个函数def div(a,b):return result# 创建一个类class MyFunction():def __init__(self,name):self.name = namedef read(self):print(self.name + '是为了帮助新手学习编程而开发的教程网站。')注意,在上述代码的第1行中我引用了 # !/usr/bin/python3 指令,这段代码的作用是告诉操作系统应该使用哪个解释器来执行这个脚本文件,在我们编写程序的时候最好都在第一行中指定这一行命令,帮助脚本和解释器版本联系起来。
另外,也可以在代码的开头添加 # -*- coding: UTF-8 -*- 指令,让程序是以 UTF-8 编码运行,防止出现乱码的情况。
接下来,我们在 my_model.py 的同级目录下创建一个 test.py 文件,在 test.py 文件中分别调用变量、函数、类来进行测试,代码如下:
# !/usr/bin/python3# Filename: test.pyfrom my_model import my_valuefrom my_model import divfrom my_model import MyFunction# 输出变量结果print(my_value)# 输出函数结果div(10,5)print(div_result)# 输出类结果MyFunction('牧旗教程')read()运行 test.py 文件,输出结果如下:
牧旗教程
2.0
牧旗教程是为了帮助新手学习编程而开发的教程网站。
我们在 test.py 的文件中使用 import 关键字依次调用了 my_model.py 文件中的变量、函数和类,可以看出,虽然是在两个文件中,但是通过 import 可以将文件中的内容引用到另一个文件中。
__name__ 属性和应用
__name__ 是一个内置属性,在 Python 的每个模块文件中都可以使用代码进行调用,其含义是代表当前模块的名称。
要注意的是,当模块在其他文件中调用时,__name__ 的值为模块的实际名称,而当模块被直接运行时,__name__ 的输出值为 __main__ 。
在介绍 __name__ 的应用之前,让我们先了解一个模块的知识,那就是当我们在引用一个模块时,该模块内的所有程序都会被执行,包括我们的测试代码,来看一个例子:
【示例】 首先我来创建一个 my_model.py 文件,作为模块文件,在该文件里写下如下代码:
# !/usr/bin/python3# Filename: my_model.py# 创建一个变量'牧旗教程'# 创建一个函数def div(a,b):return result# ----下面是在模块中添加的测试代码----print('下面是测试代码')print(my_value)print(div(10,5))在上面的模块中,我新增了一些测试代码用于测试功能,如果此时执行 my_model.py 会输出对应的结果,那么接下来我创建引用程序文件为 test.py ,在这个文件中引入该模块:
# Filename: test.pyimport my_model接下来,我运行 test.py 文件,可以看到输出了以下的结果:
下面是测试代码
牧旗教程
2.0
可以看出,我在 test.py 中调用了 my_model 模块,只进行了 import 操作,没有调用里面的任何变量、函数或者类,但是由于模块文件本身存在测试代码,所以 test.py 文件中也会运行模块中的代码输出结果,这显然不是我们想要的效果。
所以为了避免这种情况出现, __name__ 属性就显得尤为重要,因为当模块直接运行时,__name__ 的输出值为 __main__,当模块在其他文件中被调用时,__name__ 的值为模块的实际名称。
因此,在模块中使用 __name__ == '__main__' 这段代码可以保证指定代码只在模块本身运行时才会启动,在被其他文件调用时不会运行,来看一下案例帮助理解:
这次我修改 my_model.py 里面的文件,将测试代码放在 if __name__ == '__main__' 下面。
# !/usr/bin/python3# Filename: my_model.py# 创建一个变量'牧旗教程'# 创建一个函数def div(a,b):return result# ----下面是在模块中添加的测试代码----if __name__ == '__main__':print('下面是测试代码')print(my_value)print(div(10,5))接下来我再次在 test.py 这个文件中引入该模块:
# Filename: test.pyimport my_model同样,我们运行 test.py 这个文件,这次会发现结果中并没有输出任何测试代码结果,因为我们在 my_model.py 中将测试代码放在 if 语句下面,此时 __name__ 的值是 'my_model' 也就是模块的文件名,由于 __name__ 和 '__main__' 不相等,所以下面的测试代码不会在 test.py 文件中运行。
关注公众号【牧旗教程】,回复“更多例题”,获取更多题型进行训练~
您的打赏将帮助维护网站服务器的正常运营,并为作者的后续更新提供更多的动力。


 点击获取
点击获取  15259239677
15259239677  354735535@qq.com 域名证书
354735535@qq.com 域名证书  京公网安备11010502053818
京公网安备11010502053818
Copyright © 2013-2023 Muqi Course. All Rights Reserved. 牧旗教程 版权所有 京ICP备2023029281号